
人类和 AI Agent 的最佳配合方式,还没被发明|对谈 Paperboy
人类和 AI Agent 的最佳配合方式,还没被发明|对谈 PaperboyPaperboy 正在尝试找到一种更自然、更连续、更可协作的 Agent 界面与记忆结构——Agent 应该通过观察你用电脑来自己学习,用 IM 而不是 session 来组织对话,主动找你,而不是等你 prompt。
来自主题: AI资讯
11574 点击 2026-06-04 20:53
 搜索
搜索
Paperboy 正在尝试找到一种更自然、更连续、更可协作的 Agent 界面与记忆结构——Agent 应该通过观察你用电脑来自己学习,用 IM 而不是 session 来组织对话,主动找你,而不是等你 prompt。

如今想写出一篇结构严密、用词专业的文章已经不算难事,只需要敲几个 prompt 生成式 AI 就能瞬间给你一篇成千上万字的文章。布鲁金斯学会去年的一项调查显示,拥有学士学位的成年人中有 35% 的人在工作中使用 AI 来撰写或编辑文档。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
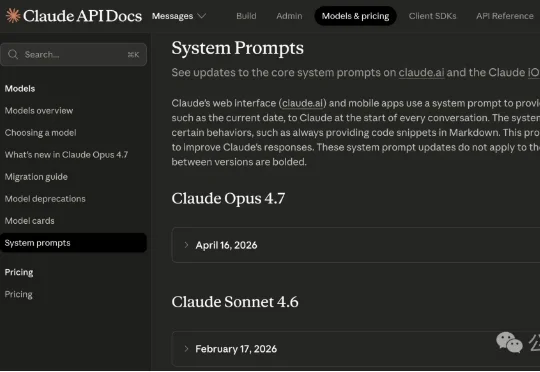
就在前两天,Anthropic祭出Claude 4.7的同时,照例公开了Claude 4.7的「驯化手册」,也就是那份系统提示词(system prompt)。Simon Willison在博客中对这份system prompt进行了逐行对比,哪里加了、哪里删了、哪里改了措辞,全部标了出来。

今天早上,OpenAI突然宣布一个促销政策:未来 30 天内,企业用户如果迁移到 Codex,2 个月免费 Codex 用量。同期,桌面端还内置了迁移工具,可以把 Claude Code 的 system prompts、custom skills、chat history、MCP server 配置一键搬过来。
AI 的熟手玩家,都应该知道system prompt这个词:每一个你用过的 AI 助手,背后都有一份你看不见的文件,却对模型有着决定性的作用。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。
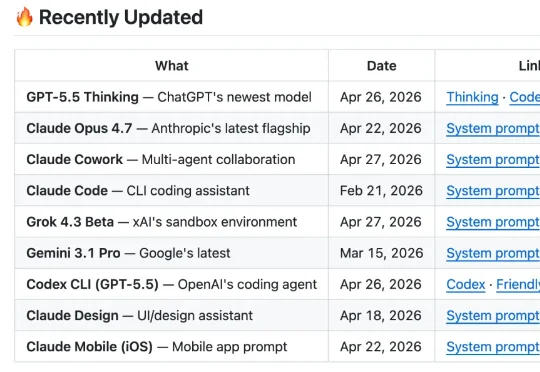
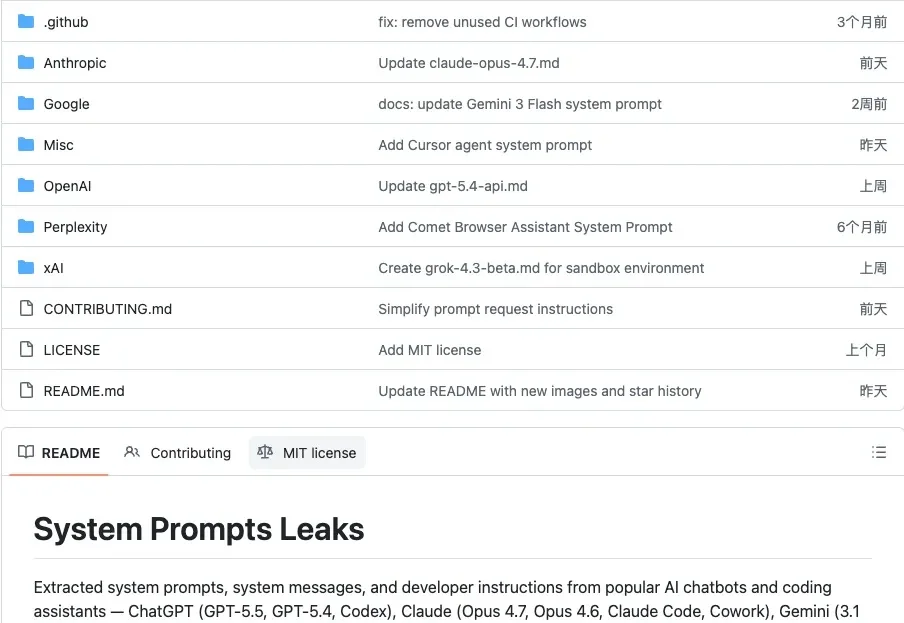
最近发现 GitHub 上有个 4 万多 Star 的开源项目(system_prompts_leaks),干了一件事:把市面上几乎所有顶级 AI 产品的 System Prompt,全部扒了出来。ChatGPT、Claude、Gemini、Grok、Claude Cowork、Codex、Perplexity....你能叫得出名字的,基本都有。
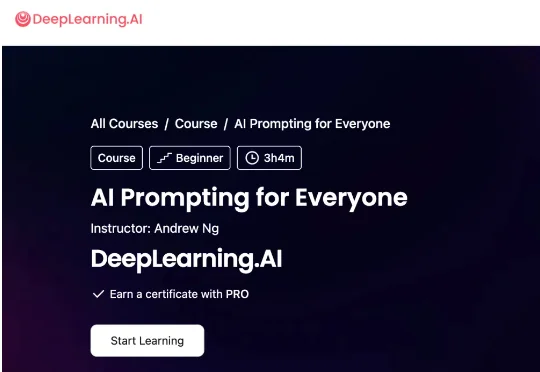
吴恩达老师又出新课了。5月1号刚刚上线的这次教的是提示词。课程名叫 AI Prompting for Everyone,在 DeepLearning.AI 平台上线,由吴恩达本人主讲,面向所有人,不需要任何技术背景。

Anthropic 的工程师们写了篇技术博客,标题是:构建 Claude Code 的经验教训:Prompt Caching 就是一切。Anthropic 内部把 Prompt Cache 的命中率当作基础设施级别的指标来监控,地位跟服务器 uptime 差不多。一旦命中率下降,就会触发 oncall 告警,工程师得像处理线上事故一样去排查。